

利用大模型的生成能力构建 AI 角色,从而丰富动漫角色、游戏NPC、甚至复活历史人物等,已经成为一个大的市场。
然而,大部分模型的表现往往过于刻板、僵硬,很难构建具有个性和风格化的生成角色,随着对话轮次的增加,回复也会偏离最初的设定,难以和人们建立深层的情绪连接。
基于对上述问题的思考以及对大模型的深入研究,清华 CoAI团队、聆心智能团队、GLM 技术团队提出 CharacterGLM,参数大小从 6B 到 66B,它是专门用于定制中文AI角色的模型,使用门槛更低,模型表现更好。
目前我们已经提供了 CharacterGLM-66B 版本的 API:https://maas.aminer.cn/dev/api#characterglm
与此同时,我们正式将 CharacterGLM-6B 模型开源:https://github.com/thu-coai/CharacterGLM-6B
基于CharacterGLM,团队研发了全新 AI 虚拟聊天陪伴产品 AiU,现已上架各大应用商店。同时,团队近期开发了恋爱攻略游戏:哎呦,恋爱怎么这么难!https://aiu.ai-topia.com/game/game/list

欢迎使用。
论文链接:https://arxiv.org/abs/2311.16832

设计原则
AI角色变“活”的强心针?
一个对话式的AI角色要想表现的像一个栩栩如生的人,必定需要具备“人的特质”,特别是人在语言表达中的文本形式特征。团队将人的语言表达特征的重点落实在属性和行为上:属性主要影响语言表达的内容,行为则影响语言表达的风格和口吻。
属性:CharacterGLM的设计主要考虑了七种属性,包括身份、兴趣、观点、经历、成就、社交关系和其他。
行为:行为主要由一些动态的元素组成:语言特征、情感表达和互动模式。例如,老年人更倾向于使用一些更正式的语言,而青少年则更喜欢用网络流行语。CharacterGLM则主要考虑了语言学特征和性格作为行为方面的设计。
AI角色是否“活”的照妖镜?
一个对话式的AI角色要想证明自己是一个栩栩如生的角色,需要具备真实的人所具备的表达特质。团队主要关注三个方面的表达特质:一致性、拟人化和吸引力。
一致性:角色一致性是角色在交互期间展现稳定的属性和行为的能力。维持一个会话式AI角色在对话中属性和行为的一致对于赢得用户的满足和信任是至关重要的。
拟人化:角色拟人化要求角色在与用户的交互中表现自然,类似人与人之间的自然交互。类人的会话式AI角色对于提高用户的接受度以及促进更自然和有吸引力的对话是不可或缺的。
吸引力:吸引力是会话式AI角色引起用户兴趣以及促进用户参与的衡量依据。聊天过程中,让对话有趣,让人想聊下去会直接影响用户的体验,这也是对话模型整体性能的一个体现。
设计方法
依据设计原则,团队收集了包含属性和行为的角色描述,并众包构建了一个大规模高质量的对话数据集,将角色描述转化为了自然语言提示,进而使用从 6B 到 66B 参数的 ChatGLM 模型进行微调来打造 CharacterGLM。除此之外,团队还收集了一部分线上交互数据来增强 CharacterGLM 的训练,以实现 CharacterGLM 的自我完善式迭代。

方法框架图
数据收集
团队主要考虑名人类、日常生活类、游戏影音类和虚拟恋爱类四种类型的角色,这些类型覆盖了大多数的场景需求,采用以下几种方式收集数据:
人类角色扮演:雇佣了大量的众包工作者两两配对,一方扮演角色另一方“玩家”,两人自由地选定对话主题进而展开对话。
大语言模型合成:使用GPT-4生成含有角色描述和对话的合成数据,并人工对合成数据中书面语对话进行了口语化的改写。
文学作品提取:人工从剧本、小说等文学作品中提取仅包含两方的对话及两方的角色描述。
人机交互:使用上面三种类型的数据训练完初版的模型后,雇佣深度用户,采用人机交互的方式收集人与CharacterGLM的多轮交互数据。
模型训练
角色prompt设计:众包工作者将数据中的角色描述形式化为流畅的自然语言描述作为模型训练的角色prompt,同时考虑总结、复述和风格化改写的角色prompt增广方式,利用Claude-2来合成多样的角色prompt。
有监督的微调:使用6B到66B参数的ChatGLM作为基座模型,将角色prompt和对话拼接在一起进行有监督的微调。
自我完善:将上面的“人机交互”数据引入有监督的微调中,促进模型的迭代式自我完善。
实验结果
除了一致性(Consistency)、拟人化(Human-likeness)和吸引力(Engagement)之外,团队使用:(1)质量(Quality)来评估回复的流畅度和上下文连贯性,(2)安全性(Safety)衡量回复是否符合道德标准,(3)正确性(Correctness)确定回复是否存在幻觉。此外,使用“整体(Overall)”指标来衡量模型回复的整体质量。
团队将 CharacterGLM 与10个中文友好的主流 LLM 进行对比,雇佣了10个标注人员,每个标注人员在11个模型上各创建两个角色,并进行不少于20轮的对话交互。交互完成后,标注人员依据上述6个子维度和整体维度进行1-5分的打分,分值越高表示模型性能越好,最后计算每个模型在各个维度上的平均分。
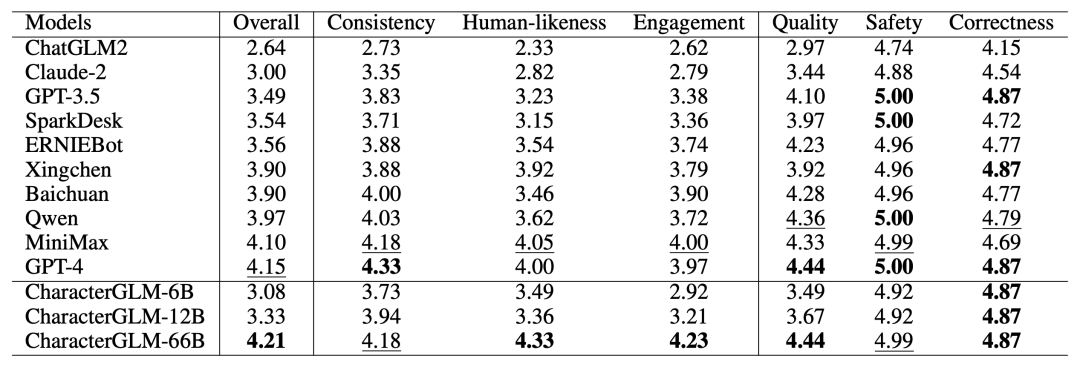
实验结果表明:
CharacterGLM-66B在“整体”评估指标中表现优异,与GPT-4不相上下。
CharacterGLM 能够平衡角色一致性、拟人化和吸引力三个关键维度,是最接近理想AI角色的模型。
CharacterGLM 的整体表现优于大多数基准模型,能够在生成高质量、内容安全和知识正确的回复上表现出优越的性能。


















